BOLT - How Mura wrote an in-house LLM Eval Framework

Hi, I’m James, one of the cofounders of Mura. We’re a seed-stage startup automating billing for commercial HVAC service providers, and over the past year, we’ve learned a lot about what it takes to build reliable AI products at scale.
This article is about how we built our evaluation system - a tool we call BOLT. It’s become critical infrastructure for how we ship improvements, migrate between models, and maintain accuracy as we grow.
When we started looking for guidance on building evals, we found surprisingly little written down, even though every AI team we talked to was building something similar. I hope sharing our approach helps other engineering teams think through their eval strategy.
Introduction
Mura is a seed-stage startup helping commercial HVAC providers get paid faster, without hiring more back-office staff. We turn messy, real-world inputs (emails, PDFs, photos, work orders) into structured data with AI and orchestration, then present suggestions with a clear, streamlined UX for our user to approve. In short: let AI do the work; let humans approve.
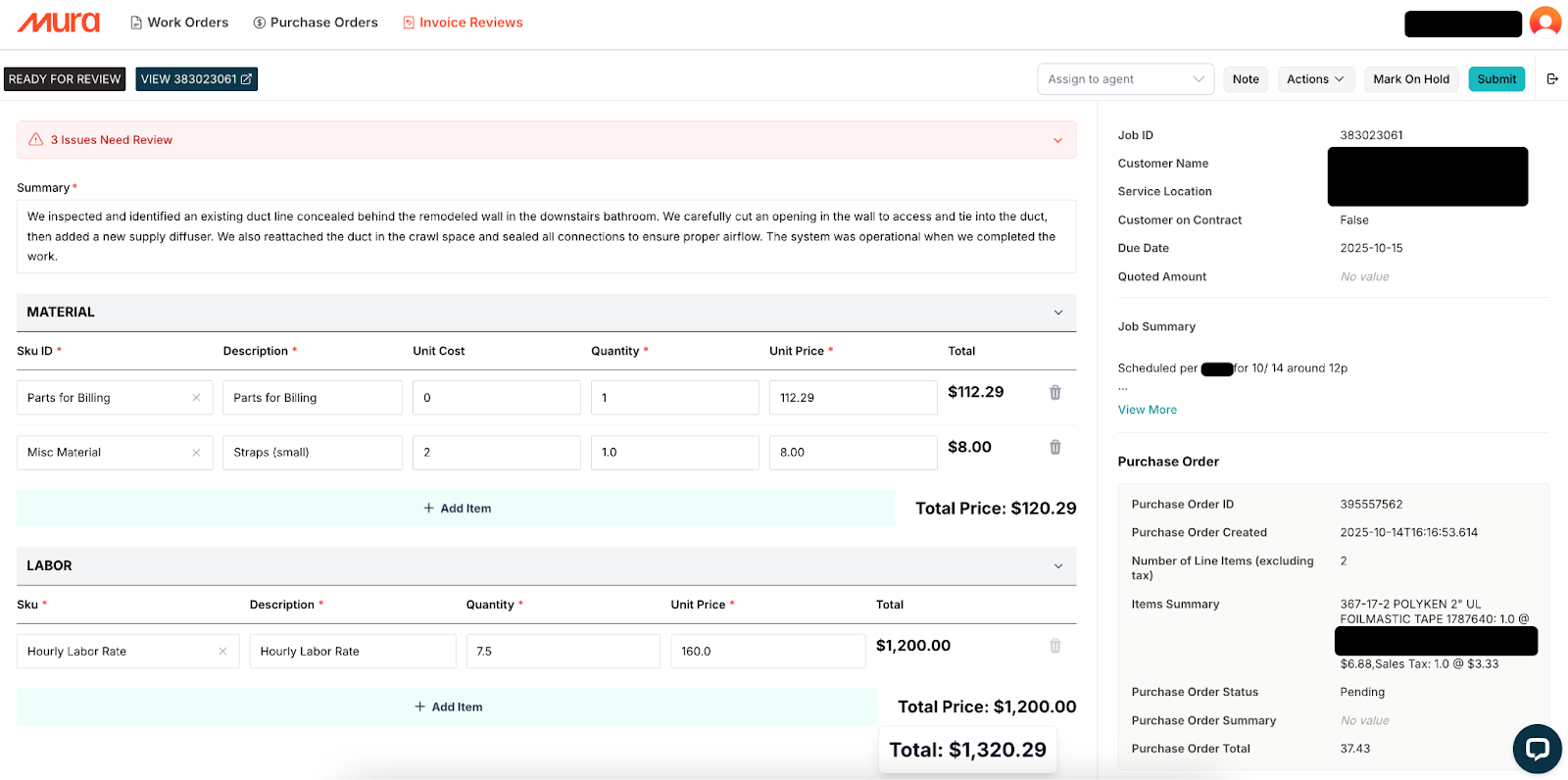
Mura’s Invoice Review Tool - The right panel shows static job context.
The left shows Mura’s suggested fields. Users can override anything before submission.
A critical internal metric is accuracy: the percentage of fields we make accurate suggestions for. The fewer mistakes Mura makes, the quicker our customers are able to get their work done, and the higher ROI they get from the product.
Early on, testing changes to prompts or prompting flows was painfully slow - each iteration took 10-20 minutes to evaluate, meaning a handful of prompt experiments could burn hours. Worse, even after testing what we thought were the important edge cases, we’d still hit parsing errors in production or get reports of unexpected behavior changes from customers.
From this experience, we realized we needed a fast, repeatable way to measure accuracy across customers, products, and model versions. Off-the-shelf “eval” tools alone don’t fit our data model or workflows, and most teams we spoke with had rolled their own. So we built BOLT (which stands for Benchmarking Outputs for LLM Testing, and pays homage to our longstanding sales tradition of playing Thunderstruck before every sales call). Since rolling out BOLT, we’ve been able to quickly and confidently improve accuracy and save costs.
Why Evals
While AI is progressing rapidly, the teams that win will be the ones that are able to quickly and safely stay on the cutting edge of progress. Great eval tools make this possible. Here’s what we needed BOLT to enable:
Model Upgrades: When a new model comes out, test that model across hundreds of use cases, understand if the new model does better or worse, and make confident migration decisions.
Customer fine-tuning: When a new customer is launched, run 10-20 test cases through Mura to make sure that the outputs look good, and re-run if we need to make custom prompt changes for that customer.
System Rearchitectures: We expect our systems to evolve from “Constrained Agents” (deterministic code calling LLMs) to “Flexible Agents” (agents given tools and context to solve problems themselves) (h/t Rahul Sengottuvelu). BOLT needs to be resilient to fundamental changes in how our systems operate.
Core Requirements
Given these goals, unit tests for prompts wouldn’t cut it. They’re valuable, but we’re constantly evolving how prompts work together as models improve. We needed to test at a higher abstraction level - evaluating end-to-end processing outputs on a field-by-field basis.
For some context on requirements, let me introduce some basic concepts in Mura’s data model:
Entity Types - The types of workflows we automate (Work Orders, Purchase Orders, Invoice Reviews)
Entity - Specific instances of an entity type - a particular work order or invoice that we generated values for. Each test case tests a complete entity.
Entity Field - Individual items we suggest values for, with metadata about field type (number, string, etc.) and name. In our UI screenshot above: summary, first SKU ID, second SKU ID - each is an entity field.
There are 3 core capabilities that we need:
Add a test case to our test set: Automatically pull metadata (entity type, customer, system of record) to enable targeted testing.
Run tests: Execute any collection of entity tests (all for a customer, all for an entity type, a specific case, etc.).
Analyze the performance: Easily compare test entity field values against expected values and previous test runs.
How We Built It
We started by surveying the market for tools that we could use parts of. We signed up for trials of Vellum, Weights & Biases Weave, Patronus, and considered being a design partner for a pre-seed company. For each of these, we felt the products were either too immature or too opinionated about code structure in a way that felt restrictive.
The most promising platform was Braintrust. They had a clean, intuitive product, were recommended by a frontier lab we work closely with, and most importantly, nailed test result creation and visualization (what they call Experiments). We ended up using Braintrust’s Datasets and Experiments functionality as some of the core primitives in BOLT.
Datasets
Braintrust’s datasets store test cases you want to revisit. We use them like this:
Each record represents one entity, with metadata like entity type, customer, and system of record.
We maintain just one dataset each for dev and prod, storing all test cases with arbitrary metadata.
At test time, we filter by metadata to run targeted test subsets.
This was a nice-to-have feature that saved us from managing a separate test case database.
Experiments
Experiments allow us to report an input, output, expected value, scoring function, and other metadata. Here is how we structured ours:
Entity fields as individual evals: Each entity field is its own eval within an experiment. The input uniquely identifies the field, letting Braintrust compare the same fields across experiments.
Field-type-specific scoring: We evaluate differently based on field type:
Numbers: Convert to float and check absolute equality
Strings: Calculate Levenshtein distance to measure similarity
Other types: Custom scoring logic as needed
The real power: Visualizations. The experiment UI gives us dense, actionable information:
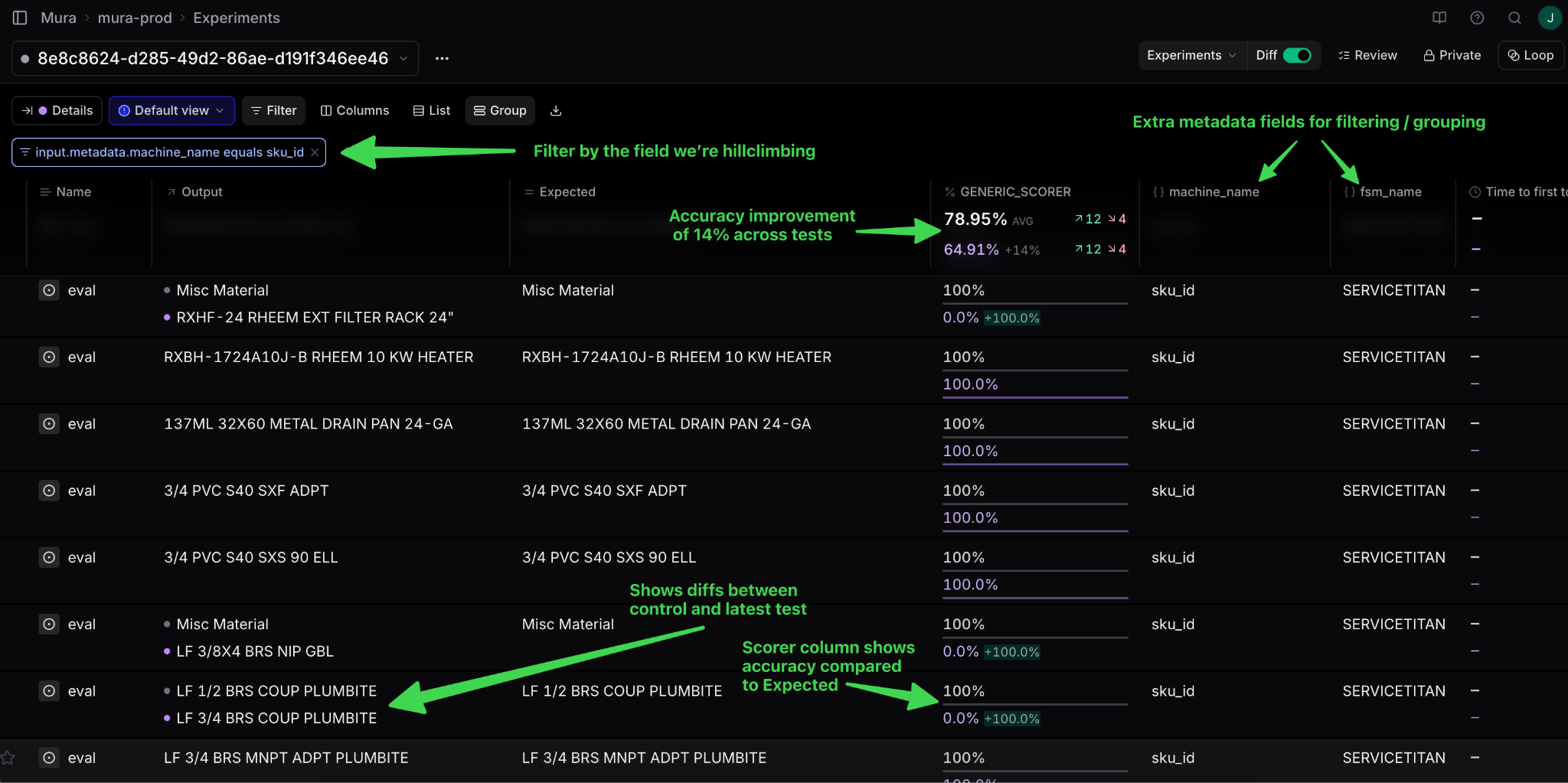
This is an extremely information dense page, so I’ll highlight a few things:
Output: What Mura generated
Expected: What a user reviewed and submitted in Mura (our source of truth, since it passed validation)
Metadata: Field name, customer name, entity ID - filterable and groupable for easy analysis
Generic Scorer: Mura’s overall accuracy rate across all fields and entities
Diff Mode: Compare against a previous experiment. Matched inputs show side-by-side, and the Generic Scorer shows performance deltas. Critical for ensuring corner case fixes don’t break existing functionality.
Braintrust’s Experiments visualization would have been very hard for Mura to replicate internally, and it would not have been as robust as what Braintrust offers. These visualization tools are ultimately why we are using Braintrust.
Filling in the pieces
With Datasets and Experiments handling test case storage and visualization, we built BOLT as a CLI to tie everything together. Developers are our primary users, and a CLI is the fastest way to integrate into their workflow.
The CLI handles two main operations:
Adding test cases is straightforward—pass in an entity ID, and BOLT looks up the metadata and pushes it to Braintrust Datasets.
Running tests requires more orchestration. BOLT spins up our application, runs multiple entity workflows concurrently, tracks expected values, and reports field-level results to a Braintrust Experiment. None of this is particularly complex, but it’s critical for making the testing loop fast.
The architecture works well because we own the Mura-specific parts (how we spin up our app, what “expected” means) while Braintrust handles the visualization and comparison heavy lifting.
Using BOLT and Future Development
Right now, BOLT is a developer experience tool. The workflow looks like:
Add a corner case that’s not handled to the BOLT testing dataset.
Run BOLT against that case plus related tests. Iterate until it works well.
Ship the change with confidence.
There are 2 areas of further development we are excited about:
Autonomous Iteration: Braintrust recently released an MCP server, which means Claude Code could potentially run BOLT experiments, analyze results, and iterate autonomously. If we can get this working, it could dramatically accelerate our development cycle.
Expanding access beyond engineering: Ultimately, we see BOLT living in Mura’s UI, so that Mura CSMs and eventually customers will be able to make configurable prompt changes in settings and immediately see how results change.
Impact
Since launching BOLT, we’ve seen dramatic improvements in development speed and product outcomes. A few examples to highlight:
Model Upgrades: Before BOLT, we never even attempted one of these migrations because of the sheer amount of hand-testing that would be required. During one of these migrations (e.g. from GPT-4 to GPT-5), we actually found that actually the smaller version of the newer model (e.g. GPT-5-mini) performed as well as the bigger model, so we are able to get more accurate results and save >80% on costs for that use case.
Customer fine-tuning: There have been a number of times when we’ve needed to update a customer specific prompt. Sometimes in our prompts we’re asking for 5 fields at a time. We’ve seen in these cases that when we add a more detailed prompt for field A, that can make the accuracy of field B drop. Since rolling out BOLT, we’ve been able to roll out prompt updates on a per-customer basis (as well as more broadly) with much more confidence that other fields were not being affected, and without the excessive testing time that this usually took.
System Rearchitectures: We are in the process of testing out a Constrained Agent => Flexible Agent migration. No results yet, but BOLT’s existence makes the paradigm shift feasible. If this experiment is successful, we will delete 2k lines of code.
Closing Thoughts
Every AI company moving from prototype to production will need robust evals. There’s no one-size-fits-all solution, but the principles are consistent: test at the right abstraction level, make results easy to analyze, and optimize for iteration speed and confidence.
If you’re building something similar, hopefully this gives you a starting point.
P.S. We’re hiring at Mura. If problems like this sound interesting to you, we’d love to hear from you at jobs@mura.co. Please include your resume and a demo / quick description of an impressive thing you’ve built!
Thanks to Alina Mitchell, David Sharpe, Claire DeRoberts, Ryan Smith, Jacob Cooper, Mike Habib, Kevin Schaich, and Nisola Shobayo for reviewing drafts of this.
This article trully comes at the perfect time, James! It's wild how little solid guidance there is on building proper LLM eval frameworks. Your insights on BOLT are super important for anyone trying to build reliable AI products at scale. Thanks for sharing this; it really helps.